このページは2002年6月頃に作成・編集されたものです。
(変なタイトルはとくに意味はありません、気にしないでください)
- このページについて
- [2002.05.21]: このページについて
- 文字コードに関するキーワード
- [2002.06.08]: 文字コードに関するキーワード
- [2002.06.08]: 「制御文字」,「図形文字」
- [2002.06.08]: 「字体」,「字形」,「書体」
- [2002.06.08]: 「文字集合」,「符号化文字集合」,「文字エンコーディング方式」
- [2002.06.10]: 「ISO」,「JIS」
- [2002.06.16]: 「MSB」
- 符号化文字集合
- [2001.08.15]: ASCII(古いレポート)
- [2002.06.03]: ASCII(新しいレポート)
- [2002.06.09]: ISO-646
- [2002.06.09]: ISO-8859
- [2002.06.10]: JIS X 0201 (JIS C 6220) 7ビット及び8ビットの情報交換用符号化文字集合
- [2002.06.10]: JIS X 0208 (JIS C 6226) 7ビット及び8ビットの2バイト情報交換用符号化漢字集合
- 未検証の符号化文字集合
- 文字エンコーディング方式
- [2002.06.17]: Shift-JIS
- [2002.06.23]: ISO-2022
- [2002.06.30]: ISO-2022-JP
- 未検証の文字エンコーディング方式
- おまけ
- 文字コード関連リンク
- 文字コード変換ソフトのリンク
- [2002.06.03]: ASCII文字テーブル出力スクリプト
- [2002.06.09]: JIS X 0201(8bit)文字集合出力スクリプト
- [2002.06.30]: あとがき
- このページについて
-
現代のコンピューティングにおいて、欠かせない技術の一つとして「文字コード」が挙げられる。そして、現代のコンピューティングにおいて、もっとも多くの人間を悩ませている技術の一つとしても「文字コード」が挙げられる。その長い歴史は、アルファベットと基本的な数字と記号のみから成るセット「ASCII」から始まり、現在では「Unicode」と呼ばれる新時代の文字コードで、世界中の文字を統合的に扱って行こう、という試みがスタートしている。
と、まあ・・あまり大げさに考えず行きましょう(^^;
- 文字コードに関するキーワード
-
文字コードは、多くの企業/団体/ユーザに育まれ、長い歴史の中で発展してきました。異なる要求、思想が混在する中で成長してきたそのためか、文字コードに関する用語の中には、曖昧に理解され、用いられているものが多く存在します。「文字コード」という用語ですら幾つかの意味に解釈することが出来てしまいます(一般にはエンコーディング方式のことや、ある文字に割り当てられている数値のことを指すが、当の分野の総称みたいなものでもある)。
ここでは文字コードに関する基本的な用語や、曖昧に理解されがちな用語について明確にその意味を定めます。次に述べる定義の内容は、より一般的な解釈を参考にしていますが、絶対的なものではないことも留意してください。
- 「制御文字」,「図形文字」
-
- 制御文字:テキスト(文字群)の表現等を制御するために割り当てられたコード
- 図形文字:形として認識できる文字の総称
“制御文字”という言葉は末尾に“文字”が付いているので、この言葉においては文字の一種だとされていますが、図形としての表現を一切持たないにも関わらず“文字である”というのは違和感を感じずにはいられません。そこで私はこれを便宜上そう呼ぶのが流行ってしまっただけで「厳密には文字ではない」としていましたが、いろいろ知ってあらためて考えてみると自信が無くなってしまいました。そもそも私は「文字の本当の正体」など知らないのです。そこで、私はもう一つの考え方を留意することにしました。それは“制御文字は、形としての表現こそ持たないが、文字としての意味はそれぞれが持ち合わせている”というものです。
- 「字体」,「字形」,「書体」
-
- 字体:図形文字の図形表現としての形状についての抽象的概念。(JIS X 0208-1997)
- 字形:字体を手書き、印字、画面表示などによって実際に図形として表現したもの。(同)
- 書体:例えば楷書、行書、草書など、あるコンセプトに基づいてデザインされた一揃いの字形。
(『図解でわかる文字コードのすべて 著:清水哲郎』の46pを参考にさせて頂きました)
- 「文字集合」,「符号化文字集合」,「文字エンコーディング方式」
-
文字コードに関する規格は様々存在しますが、それが厳密に何を規定しているかについては曖昧な解釈が広まってしまっています。特に、ある規格が「文字集合」/「符号化文字集合」/「文字エンコーディング方式」のどれに属するものなのか、もしくはそれらの複数にまたがり属しているのか、ということはやや難解な概念ですが、文字コードを理解するためには重要なことです。
- 文字集合:何らかの要求に基づいて集められた字体の集合(通常、その順序をも含む)
- 符号化文字集合:文字集合の個々の字体が特定の整数と一対一に対応付けられた値を有する文字集合
- 文字エンコーディング方式:実際に文字を整数に符号化し扱うために集められた符号化文字集合や符号化の計算式
- 「ISO」,「JIS」
-
ISO(International Organization for Standardization)は国際規格の標準を定める団体で、JIS(Japan Industrial Standards)は日本国内の工業規格の標準を定める団体です。ISOから発行された規格はそのまま用いられるのではなく、各国が同じ内容を国内規格として再発行して用いられることになっているらしいです。例えば、複数の文字集合を切り替えて利用する方法の標準を定める ISO-2022 は日本国内では「JIS X 0202」として再発行されています。
JIS規格に関することで、心得ておきたいことが一つあります。正確にいつ頃のことなのかは不明ですが、JISの団体そのもののグループ変えがあり、それに伴って規格の命名形式が変更されました。これにより、文字コードに関する各規格にも“JIS C”(“C”はおそらくCharacterのC)から始まる旧式名称の他に、“JIS X”(“X”はコンピュータに関する規格を意味するらしい)から始まる新式名称が定められました。プレフィクスが異なるだけならまだしも、その後に続く番号にも変更が施されていることに注意してください。現在では新式名称が主たる呼び名になっています。なお、この文書でも原則的に新式名称を用いていますが、規格名のタイトルには括弧内に旧式名称も示しています。
- 「MSB」
-
プログラマ向けに専門意識の強い言葉なので、おそらくこんな略語は知らない読者が多いこととは思いますが、意味を理解していればとても便利な言葉なので、私はときおり使用しています。
MSB は Most Significant Bit の略で「最上位ビット」と訳されます。最上位ビットとは、データを 0 と 1 のビット列で表現したときに一番左側に位置し、一番大きな数を司るビットのことです。例えば、次のビット列はアルファベットの A の文字コードです。MSB には下線を引きました。
01000001文字コードの分野では、7bit をベースとした規格はこの MSB を利用していず、8bit をベースとした規格は MSB を利用している、という事実があるのでこの言葉を用いると説明を簡潔にできることがあります。例えば、“Shift-JIS は MSB を使用しているので、電子メールの扱いにおいては MSB を使用しない JISコードを利用した方が安全である”などという言い方ができます。なお、文字コードの分野では関係ありませんが、プログラミングの分野では LSB(Least Significant Bit(最下位ビット)) という一番右側に位置するビットのことを指す言葉も使われます。
- ASCII([2001.08.15]公開版)
-
(*>ASCIIのレポートは[2002.06.03]にグレードアップした新しいバージョンを公開しました。そちらの方をご覧ください)
ASCII(American Standard Character for Information Interchange)とは1バイト中の上位1ビット(MSB:Most Significant Bit と呼ぶ)以外の7ビットで表現できる数 0 ~ 127 に、大小のアルファベット,数字,記号,それに制御文字(コントロールコード)を割り当てたアメリカの工業規格のことです。文字コードを理解するのにまず押える必要のある基本的なキャラクタ・セットです。
コントロール・コード(0 ~ 31 / 127)
5ビットで表現できる数 0 ~ 31 と、7ビットで表現できる最大の数 127 には改行や水平タブのような制御文字が定義されています。ここでは代表的なコントロール・コードのみ紹介します。
コード(16:10) 省略記号 説明 00:000 NUL(null) 0の文字幅を示す。Cなどの言語では文字列の終わりの記号意味として使われる。 07:007 BEL(bell) 警告音を発する。環境によって異なるが、一般に「ピーッ」などの音が鳴る。 08:008 BS(Back Space) 1文字後退、直前の文字を削除する。 09:009 HT(Horizontal Tabulation) 水平タブ文字。タブ位置(環境により4文字,8文字幅など異なる)まで一気に移動する。 0A:010 LF(Line Feed) 改行。次の行に移動する。 0B:011 VT(Vertical Tabulation) 垂直タブ文字。使用例を見たことがない・・。 0C:012 FF(Form Feed) 書式送り。 0D:013 CR(Carriage Return) 復帰。行頭に移動する。 1B:027 ESC(Escape) エスケープ。 20:032 SPC(Space) 1文字幅空白。制御文字なのかどうかは曖昧だがその性質上、省略表現が存在するので一応記述しておく。 7F:127 DEL(Delete) 現位置の文字を削除する。 プリンタブル・コード(33 ~ 126)
32から126までの数には印字可能なアルファベットや数字,記号などの文字が定義されています。ASCIIコード表(32 ~ 126) [20:032] [21:033]! [22:034]" [23:035]# [24:036]$ [25:037]% [26:038]& [27:039]' [28:040]( [29:041]) [2A:042]* [2B:043]+ [2C:044], [2D:045]- [2E:046]. [2F:047]/ [30:048]0 [31:049]1 [32:050]2 [33:051]3 [34:052]4 [35:053]5 [36:054]6 [37:055]7 [38:056]8 [39:057]9 [3A:058]: [3B:059]; [3C:060]< [3D:061]= [3E:062]> [3F:063]? [40:064]@ [41:065]A [42:066]B [43:067]C [44:068]D [45:069]E [46:070]F [47:071]G [48:072]H [49:073]I [4A:074]J [4B:075]K [4C:076]L [4D:077]M [4E:078]N [4F:079]O [50:080]P [51:081]Q [52:082]R [53:083]S [54:084]T [55:085]U [56:086]V [57:087]W [58:088]X [59:089]Y [5A:090]Z [5B:091][ [5C:092]\ [5D:093]] [5E:094]^ [5F:095]_ [60:096]` [61:097]a [62:098]b [63:099]c [64:100]d [65:101]e [66:102]f [67:103]g [68:104]h [69:105]i [6A:106]j [6B:107]k [6C:108]l [6D:109]m [6E:110]n [6F:111]o [70:112]p [71:113]q [72:114]r [73:115]s [74:116]t [75:117]u [76:118]v [77:119]w [78:120]x [79:121]y [7A:122]z [7B:123]{ [7C:124]| [7D:125]} [7E:126]~この表は次の短いPerlスクリプトで出力されました。 foreach $num( 32..126 ){ printf "[%02X:%03d]%c ", $num, $num, $num; print "\n" if ++$i % 8 == 0; }上位1ビット(MSB:Most Significant Bit)を利用した文字
Shift-JISなどのコード体系ではMSBを利用して表現できる数 128 ~ 255 の中に半角カタカナなどの文字を割り当てています。このようなMSBを利用したコードを含む文書を通信でやり取りした場合、文字化けが起こりやすいという問題があります。E-mailユーザ・エージェントなどではMSBを利用しないコード体系であるISO-2022-JP(JISコード)への変換を自動的に行う場合があります。MSBが1のコード(エンコード方式により表示文字が変わります) [80:128] [81:129]・[82:130]・[83:131]・[84:132]・[85:133]・[86:134]・[87:135]・ [88:136]・[89:137]・[8A:138]・[8B:139]・[8C:140]・[8D:141]・[8E:142]・[8F:143]・ [90:144]・[91:145]・[92:146]・[93:147]・[94:148]・[95:149]・[96:150]・[97:151]・ [98:152]・[99:153]・[9A:154]・[9B:155]・[9C:156]・[9D:157]・[9E:158]・[9F:159]・ [A0:160] [A1:161]。 [A2:162]「 [A3:163]」 [A4:164]、 [A5:165]・ [A6:166]ヲ [A7:167]ァ [A8:168]ィ [A9:169]ゥ [AA:170]ェ [AB:171]ォ [AC:172]ャ [AD:173]ュ [AE:174]ョ [AF:175]ッ [B0:176]ー [B1:177]ア [B2:178]イ [B3:179]ウ [B4:180]エ [B5:181]オ [B6:182]カ [B7:183]キ [B8:184]ク [B9:185]ケ [BA:186]コ [BB:187]サ [BC:188]シ [BD:189]ス [BE:190]セ [BF:191]ソ [C0:192]タ [C1:193]チ [C2:194]ツ [C3:195]テ [C4:196]ト [C5:197]ナ [C6:198]ニ [C7:199]ヌ [C8:200]ネ [C9:201]ノ [CA:202]ハ [CB:203]ヒ [CC:204]フ [CD:205]ヘ [CE:206]ホ [CF:207]マ [D0:208]ミ [D1:209]ム [D2:210]メ [D3:211]モ [D4:212]ヤ [D5:213]ユ [D6:214]ヨ [D7:215]ラ [D8:216]リ [D9:217]ル [DA:218]レ [DB:219]ロ [DC:220]ワ [DD:221]ン [DE:222]゙ [DF:223]゚ [E0:224]・[E1:225]・[E2:226]・[E3:227]・[E4:228]・[E5:229]・[E6:230]・[E7:231]・ [E8:232]・[E9:233]・[EA:234]・[EB:235]・[EC:236]・[ED:237]・[EE:238]・[EF:239]・ [F0:240]・[F1:241]・[F2:242]・[F3:243]・[F4:244]・[F5:245]・[F6:246]・[F7:247]・ [F8:248]・[F9:249]・[FA:250]・[FB:251]・[FC:252]・[FD:253] [FE:254] [FF:255]
- ASCII([2002.06.03]公開版)
-
ASCII(American National Standard Code for Information Interchange)は、複数のコンピュータの間で円滑な情報交換を行うために1963年にANSI(アメリカ工業規格協会)が定めた7bitベース文字セットの標準です。現在、多岐に渡る文字コードが存在していますが、そのほとんどはASCIIへの互換性が重視されており、ASCII文字だけはどのような文字コードを用いていても問題なく表示できるよう考慮されています。ASCIIはあらゆる文字コードの祖先である、といえます。
コンピュータは 8bit の倍数のデータを処理の基本単位とするよう設計されています。それに対し、ASCIIは 7bit で表現可能な 128 の数値領域に制御文字や図形文字などを配置しました。アメリカで扱われるアルファベットやアラビア数字、それに図形記号や制御文字を含めても 128 の領域があれば十分だったからです。8bit に一つ足りないこの“無視された1bit”は後に、コンピュータの文字コードの歴史に大きな波を起こすことになりました。
ASCIIが定めた文字セットの表を次に示します。垂直方向に16進数1桁目を、水平方向に2桁目を表しているので、下に向かって順に数が増えるものと見てください。(この表ではCSSにより表示フォントを「Times New Roman」に指定しています。日本語フォントでは 0x5C がASCII文字と異なってしまうからです。(0x5C の文字は、ASCIIではバックスラッシュ記号だが、日本語フォントでは円記号になる))
(この表はこの短いPerlスクリプトで出力されました)【ASCII文字テーブル】 0 1 2 3 4 5 6 7 0 NUL DLE SP 0 @ P ` p 1 SOH DC1 ! 1 A Q a q 2 STX DC2 " 2 B R b r 3 ETX DC3 # 3 C S c s 4 EOT DC4 $ 4 D T d t 5 ENQ NAK % 5 E U e u 6 ACK SYN & 6 F V f v 7 BEL ETB ' 7 G W g w 8 BS CAN ( 8 H X h x 9 HT EM ) 9 I Y i y A LF SUB * : J Z j z B VT ESC + ; K [ k { C FF FS , < L \ l | D CR GS - = M ] m } E SO RS . > N ^ n ~ F SI US / ? O _ o DEL 背景をオレンジっぽい色で表したセルは、特殊な意味を持つコードで「制御文字(コントロール・コード)」と呼ばれます。これらは形としての文字表現を持たないので、慣例的に代替の略号で表されています。34つもありますが、次に列挙するもの以外は現在ではほとんど使われることはありません。
【ASCIIコントロール・コード(抜粋)】 16進 代替略号 略号フルスペル 意味 0x00 NUL Null null: C言語では文字列の終端として扱われる。 0x07 BEL Bell 警告音: ビープ音を発する。 0x09 HT Horizontal Tabulation タブ文字: テキストの整形に使われる。 0x0A LF Line Feed 改行: カーソルを次行へ送る。 0x0D CR Carriage Return 復帰: カーソルを行頭へ送る。 0x1B ESC Escape エスケープ: 用途は一定ではなく、処理系により様々である。 0x20 SP Space 空白: これは厳密には制御文字とも図形文字とも区別される。 用途不明なコントロール・コードが多数ありますが、これらは昔『テレタイプ』と呼ばれる現代のコンピュータの前身とも言える装置が情報通信に用いられていた時代の名残だと言われています。テレタイプの表示装置は現代のCRTや液晶のようなものではなく、プリンタそのものだったらしいので、このようなコントロール・コードを用いて表示やその他の制御を行っていたのでしょう。DEL(delete: 削除)だけが他のコントロール・コードと離れて一つだけ最後尾にあるのもそのためです。テレタイプは情報の記録にもやはり紙に穴を空けることによって行っていたのですが、間違えてタイプしてしまっても一度空けてしまった穴は塞ぐことが出来ないので、7Fで穴続きにすることにより「削除」の意味を表していたそうです。
テレタイプに興味のある方は次のサイトを見てみると良いかもしれません。写真を交えたテレタイプに関する記事があります。
探検隊 http://homepage1.nifty.com/plusworld/FOPENTY.HTM[2002.06.11]: 慣用句“ASCII文字”が指すもの
なお、日本国内において交わされる言葉の文脈に現れる“ASCII文字”という言葉はほとんどの場合、厳密には JIS X 0201 のローマ文字のことを指しています。この理由は、現在(2002.06.11)日本のパソコンにおける文字エンコーディング方式のデファクトスタンダードである Shift-JIS が ASCII ではなく JIS X 0201 を含んだ文字集合を採用していることにあります。とはいえ、JIS X 0201-ローマ文字集合はASCII文字集合とほぼ同様の文字集合を継承しているので、“ASCII文字”という言い方が間違いという訳でもありません。ただし、文字コード 0x5C だけは ASCIIで参照するところのバックスラッシュ記号が、JIS X 0201 では円記号“\”に置換えられている、という違いだけは意識してください。 - ISO-646
-
名前の通り、ASCIIはアメリカ国内向けに規定されたもので、その諸外国(ヨーロッパ諸国など)にとっては充分に必要な文字を満たしているとは言えませんでした。ISO-646は、この問題に対処するために1973年にISOが規格したもので、ASCIIの図形文字の内12箇所の文字を各国が要する文字と入れ替え可能とし、「自国版ISO-646」として利用することを許可したものです。オリジナルのASCIIと同じ文字集合の版も「IRV(International Reference Version: 国際参照版)」として同時に規定されています。
入れ替え可能とされた文字とは、具体的にはIRVの内、次の12文字です。
23 24 40 5B 5C 5D 5E 60 7B 7C 7D 7E ASCII Character # $ @ [ \ ] ^ ` { | } ~ ヨーロッパ諸国はこれに応じ、各国が自国版を規格したということですが、我々日本人にはさして興味のあることでもありません。しかも歴史的に大きな影響があったというだけで、現在ではISO-646はあまり使われていないようです(代わりに ISO-8859 という8bitベースの規格が用いられている)。それよりも我々日本人にとって興味があり、重要なのは、「JIS X 0201」という ISO-646 の“日本版”が存在するということです。
話しは変わりますが、ISO-646が規格化された同じ年に「ISO-2022」という複数の文字集合を切り替えて用いるための技術標準が登場しました。独立した文字集合が諸国により乱立し、複数存在することになってしまったISO-646を、整合性を保ちながら表現するために必要として生まれたのかもしれません。また、ISO-2022では従来の7bitをベースにした文字集合に関する内容だけでなく、8bitをベースにした文字集合に関する内容も合わせて規格されました。
- ISO-8859
-
ISO-646は、ASCIIの7bitベースの文字集合という性格を保持したまま、たった12文字の入れ替えを許容するものでしたが、ISO-8859は、8bitに拡張された領域(1bit増えるとその表現領域は倍になる)に各国々の固有文字を割り当てて良い、という趣旨のもとに規格化されました。この規格の実装は諸国により多数存在しますが、中でも1987年に発行された「ISO-8859-1(通称:Latin-1)」はヨーロッパ諸国の主たる文字の多くが収録されており、共通して利用できる国が多いことから一番ポピュラーなISO-8859として位置付けされています。また、ISO-8859-1は、HTMLの規格においても標準の文字集合とされているほか、日本においても欧州の文字を表す文字集合として標準の扱いになっています。
さて、8bitに拡張され、理論的には16進数で 0x80 ~ 0xFF までの計128の領域に文字を割り振ることが可能なはずですが、実際に発行されたISO-8859のどのバージョンを見ても、文字の割り当ては 0xA0 以降から始まっています。これは、どういうことなのかというと、ISO-2022 で切り替えが可能な文字集合の条件にのっとって割り当てられているようなのです(ISO-2022 では 0x80 ~ 0x9F にはコントロール・コードが配置される)。つまりISO-8859は当初から ISO-2022 に適合するよう定義されていたのです。(恐らくISO-8859の規格内容にはその趣旨が述べられているのだろうが、確認した訳ではない)
- JIS X 0201 (JIS C 6220) 7ビット及び8ビットの情報交換用符号化文字集合
-
この規格はISO-646(不明な場合は、当の項を参照のこと)の日本版であり、0x5C と 0xFE の2箇所の文字を、それぞれ“円記号”と“オーバーライン記号”に置換えたもので、1976年に発行されました。この文字集合は通称「JIS X 0201ローマ文字集合(又は、ISO-646ローマ文字集合。“ローマ”の代わりに“ラテン”ということもある)」と呼ばれます。ただし、この規格はそれだけに留まらず、国内のニーズに応えてカタカナ文字集合をも規定しています。この文字集合は通称「JIS X 0201カタカナ文字集合(又は、ISO-646カタカナ文字集合)」と呼ばれます。
カタカナ文字集合の配置体系は、8bitに拡張された領域に割り当てるタイプと、7bitの領域に割り当てるタイプとの二通りあります。7bitタイプの場合、当然ながらカタカナ文字集合とローマ文字集合との文字コードが衝突してしまいますので、この二つの文字集合を制御文字 SO(Shift-Out), SI(Shift-In) を用いて切り替えながら利用することが規定されています(この方法は ISO-2022 規格の一部)。8bitタイプを用いることを標準とすればこのような面倒な切り替え処理は不要なところをわざわざ二通りの方法を定めたのは、8bitに拡張された文字集合に対応していないISO-646に対し互換性を維持する体制をとった為です。JIS X 0201 の正式名称「7ビット及び8ビットの情報交換用符号化文字集合」からも分かる通り、つまり 7bitベースの文字集合でも 8bitベースの文字集合でもあるのです。
以下に JIS X 0201 の 8bitベースの文字集合の表を示します。現在において、JIS X 0201 の文字集合が直接利用されるケースはほとんど無い(7bit, 8bit 両ベースの集合とも)と思われますが、現在パソコンにおける文字エンコーディング方式のデファクト・スタンダードである Shift-JIS が JIS X 0201(8bit) に対し、完全な互換性を保って開発された歴史的経緯などの理由から、現在でも JIS X 0201(8bit) は頻繁に参照される重要な文字集合です。
【JIS X 0201 - 8bitベース文字集合】 0 1 2 3 4 5 6 7 8 9 A B C D E F 0 NUL DLE SP 0 @ P ` p ー タ ミ 1 SOH DC1 ! 1 A Q a q 。 ア チ ム 2 STX DC2 " 2 B R b r 「 イ ツ メ 3 ETX DC3 # 3 C S c s 」 ウ テ モ 4 EOT DC4 $ 4 D T d t 、 エ ト ヤ 5 ENQ NAK % 5 E U e u ・ オ ナ ユ 6 ACK SYN & 6 F V f v ヲ カ ニ ヨ 7 BEL ETB ' 7 G W g w ァ キ ヌ ラ 8 BS CAN ( 8 H X h x ィ ク ネ リ 9 HT EM ) 9 I Y i y ゥ ケ ノ ル A LF SUB * : J Z j z ェ コ ハ レ B VT ESC + ; K [ k { ォ サ ヒ ロ C FF FS , < L \ l | ャ シ フ ワ D CR GS - = M ] m } ュ ス ヘ ン E SO RS . > N ^ n ~ ョ セ ホ ゙ F SI US / ? O _ o DEL ッ ソ マ ゚ 二箇所の赤っぽい背景のセルにあるのが ISO-646 の国内版として置換えられた文字です。ASCII の 0x5C のバックスラッシュが円記号に置換えられたのは有名ですが、0x7E のチルダがオーバーライン記号に置換えられたのはあまり有名ではありません。それというのも、1976年に発行された JIS X 0201 では確かに置換えて規定されたはずなのですが、ソフトウェア産業界にはあまり受け入れられなかったようで、実際、ソフトウェア上では置換えされているケースは少ないようなのです(上の表でもチルダのままで表示されていると思います)。それに対し、ハードウェア産業界では受け入れられたようで、実際、キーボード右上のひらがなの「へ」がこの文字に対応するのですが、オーバーライン文字が刻印されている機種が多いはずです。しかし、1997年に行われた JIS X 0201 の改訂で、“0x7Eに対応する文字はチルダでもオーバーラインでも構わない”との方針が述べられたということで、近年生産されたキーボードは既にチルダの文字が刻印されるようになっていることでしょう。
文字コードに関する話題としてよく挙がる「Windowsのディレクトリ区切り記号はなぜ円記号“\”なのか」ですが、この理由には少々回りくどい歴史的な経緯が絡んでいます。過去にさかのぼる順番でリスト形式による説明をします。
- Windowsのディレクトリ区切り記号は本来は円記号ではなくバックスラッシュ記号であるが、日本においては主に JIS X 0201 に準拠した文字集合が利用されるためにバックスラッシュに相当する文字コードが円記号で表示されてしまう。
- Windowsの前身であるMS-DOSの時代からディレクトリ区切り記号はバックスラッシュであったために、Windowsもそれを踏襲した。
- MS-DOSはUNIXを見習い、ディレクトリ区切り記号にスラッシュ“/”を採用しようとしたが、スラッシュは既にコマンドの引数を示す記号として使われていたためにそれが出来ず、代わりによく似た記号であるバックスラッシュを採用した。
[2002.06.15: JIS X 0201(8bit) の未定義領域と Shift-JIS]
上の表を見ると 0x80 ~ 0xA0 と 0xE0 ~ 0xFF の領域が未定義になっていることに気付くと思います。現在、パソコンにおける文字エンコーディング方式のデファクト・スタンダードの地位を築いている Shift-JIS はこの未定義領域に目を付け(笑)ました。Shift-JIS はその全ての設計方針に JIS X 0201(8bit) を基礎に置き、JIS X 0201(8bit) と JIS X 0208 の文字集合をエスケープ・シーケンス等を用いずに混在させる仕組みを実現させています。 - JIS X 0208 (JIS C 6226) 7ビット及び8ビットの2バイト情報交換用符号化漢字集合
-
JIS X 0208 は1978年に制定された2バイト・ベースの符号化文字集合です。漢字(第一水準、第二水準)/ひらがな/カタカナ/アラビア数字/ローマ字/ギリシャ文字/記号やその他の文字、など総数6869(この数は改訂版 JIS X 0208:1997 での数)の文字を収録しています。俗に「JIS漢字」と呼ばれますが、漢字のみに焦点をおいたこの呼び名は誤解されやすいものです。制定以来、1983年、1990年、1997年というように現在(2002.06.10)まで三回の改正が行われていますが、ここでは特に重要な1983年の改正にのみ触れています。
「旧JIS漢字」,「新JIS漢字」という呼ばれ方をご存知でしょうか。JIS X 0208 は1983年の改正時に、漢字の「旧字体」,「新字体」の相違による字形の違いを意識した大規模な改変が行われました。これにより、1978年版の JIS X 0208 を採用したコンピュータで入力した文字を、1983年版の JIS X 0208 を採用したプリンタなどに出力すると、実際に印刷される文字が異なってしまう、というような問題が発生し、大きな混乱を起こしました。そのような経緯から、改正される以前の JIS X 0208 を「旧JIS漢字」と、改正された以後の JIS X 0208 を「新JIS漢字」と俗称し、区別されるようになったのです。
JIS X 0208 は2バイト・ベースの文字集合ですが、従来よりの JIS X 0201(7bit) などの7bitをベースとした文字集合との共存性を重視し、両バイトともMSB(最上位ビット)は利用されず、7bitをベースとして表現されることになりました(*)。JIS X 0201 のコード領域の内、制御文字と空白文字を除いた 0x21 ~ 0x7E の94の図形文字領域を二つ(=2バイト)並べることにより 94 * 94 = 8836 の領域を確保し、そこに各種の文字を配置しています。
(*正式名称から察するに、8bitをベースとした規格も含まれるようなのですが、少なくとも確かなことは“それは重要ではない”ということで、私もその内容は知りません)
JIS X 0208 による1バイト文字と2バイト文字の扱いのコンセプトのイメージを以下に示します。これは、Shift-JISのコンセプト・イメージと見比べると、その違いがよく分かります。
【JIS X 0208 コンセプト・イメージ】 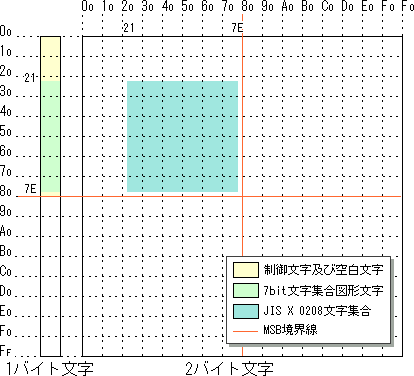
さて、JIS X 0208 では文字コード領域に 0x21 ~ 0x7E の範囲、つまり完全に JIS X 0201 の文字コード領域と重複する範囲を利用していますが、JIS X 0201 の1バイト文字と JIS X 0208 の2バイト文字を並べたときにどのようにして1バイト文字と2バイト文字の違いを判断しているのでしょう?Shift-JIS のように特有の数値を持つコードで1バイト文字と、2バイト文字の1バイト目とを見分けられないのでは全て1バイト文字だと判断してしまわないでしょうか。JIS X 0208 ではこのような不定数のバイト列や、また、異なる文字集合の混在したテキストを「エスケープシーケンス」と呼ばれるある種のスイッチのような意味を持った符号を挿入することにより可能にしています(これは ISO-2022(JIS X 0202) の部分実装です)。以下に JIS X 0208 で用いられるエスケープシーケンスの表を示します。
切り替える文字集合 16進数表記 ASCII文字表記 ASCII 1B 28 42 ESC ( B JIS X 0201ローマ字 1B 28 4A ESC ( J JIS X 0201カタカナ 1B 28 49 ESC ( I JIS X 0208:1978(旧JIS漢字) 1B 24 40 ESC $ @ JIS X 0208:1983(新JIS漢字) 1B 24 42 ESC $ B ([2002.06.15]: JIS X 0208 は文字エンコーディング方式を含む文字集合?
JIS X 0208 は、文字エンコーディング方式である ISO-2022 の一部を実装しているようなので、JIS X 0208 は単なる符号化文字集合ではなく文字エンコーディング方式の性格を併せ持つ文字集合なのかもしれません。いずれにせよ、現在では JIS X 0208 が直接単独で実装するケースはなさそうで、JIS X 0208 は単なる符号化文字集合として扱われています。)ところで、JIS X 0208 では JIS X 0201 で既に定義されていたローマ字やカタカナなどが改めて2バイト文字として定義されています。しかし、この規格は前述の通り JIX 0201 のローマ字やカタカナの文字集合と同時に利用するものであったため、結果として JIS X 0208 に準拠した環境で記述されたテキストは JIS X 0201 の1バイトのローマ字やカタカナと、JIS X 0208 の2バイトのローマ字やカタカナの文字が混在することになりました。「半角文字」や「全角文字」というよく知られた呼び方がありますが、これは JIS X 0208 の2バイト文字の幅が丁度 JIS X 0201 の1バイト文字の倍程度であったため、JIS X 0201 の文字を“半角”、JIS X 0208 の文字を“全角”などと俗称されたことが発端です。
[2002.06.15]: JIS X 0208 は情報交換用の文字集合
これは見落としがちなことなのですが、JIS X 0201 や JIS X 0208 は正式名称からも分かる通り、本来は“情報交換用の文字集合”です。この為に、通信媒体上での情報伝達のようなシーケンシャル・アクセス(先頭から順々に読み込むということ)を主とした利用の観点においては問題はないのですが、ソフトウェアの内部処理のようなランダム・アクセス(読み込む位置や順番が決まってないこと)を主とした利用の観点から見ると、このようなある文字の判断が、そのものの文字コードのみならず前方のエスケープ・シーケンスの出現に依存するような方式は“不便で不向き”としか言えません。その為、自然とソフトウェア・ベンダはエスケープ・シーケンスを用いない文字エンコーディング方式で、それでいて JIS X 0208 の文字集合をすべて含む Shift-JIS を採用するようになりました。 - 未検証の符号化文字集合
-
次に列挙する項目は、その存在は確認していたものの、諸々の事情で詳しい検証まで至ることが出来なかった符号化文字集合の規格らです。機会があれば検証に踏み込むかもしれません。
- JIS X 0212(JIS補助漢字)
- Windows符号化文字集合
- Macintosh符号化文字集合
- JIS X 0211 符号化文字集合用制御機能
- Shift-JIS
-
[概観,特徴]
Shift-JIS はOSなどソフトウェアの内部処理用の文字エンコーディング方式として開発されました。これは、ISO-2022 のようなテキストにエスケープ・シーケンスを挟んで複数の文字集合を切り替えて使用するような方式に対し、“もっと単純に扱え、ランダム・アクセスが簡単に出来る方法はないか”という要望により生まれたものです。Shift-JIS はエスケープ・シーケンスを一切挟むことなく JIS X 0201(8bit) と JIS X 0208 の文字集合のすべての文字を含むことが出来ます。内部処理用の文字エンコーディング方式として Shift-JIS を採用することによりソフトウェアの開発は飛躍的に楽になったと言われます。[生まれ,公的規格でない理由]
ISO-2022 のように前後のエスケープ・シーケンスの存在に依存されず多くの文字を表現可能な Shift-JIS のような便利な文字エンコーディング方式が何故もっと早期に公的機関により開発されなかったのでしょう?(Shift-JIS は“JIS”という語句を含むものの、JIS により制定された公的な規格ではありません。そもそも“Shift-JIS”という呼び名すら通称であり、正式名称ではありません。)文字コードの歴史は ASCII を筆頭に 7bit をベースとした規格を中心に発展してきました。日本でも JIS X 0201 という 8bit をベースとした内容を含む一方で、7bit をベースとした内容も含む文字集合の規格が生まれました。さらに文字集合の中に漢字を含む JIS X 0208 という日本にとって重大な規格が生まれましたが、注目すべきことに、これが 7bitベースの JIS X 0201 に対し後方互換を保って設計されているのです。つまり公的機関では旧来への互換性を重視し、MSB(8bit目)を利用する設計方針に対しては否定的だったのです。そして、さらに注目すべきは Shift-JIS は JIS X 0208 とは異なり 8bitベースの JIS X 0201 をその全ての仕組みの基礎としていることにあります。
(補足:非公的な技術である Shift-JIS ですが、パソコン業界においてデファクト・スタンダードの地位を築くほどの功績を追認する形として 1997年の JIS X 0208 の改訂時に“付属書”という扱いで公認された、という話しです。)[真意,コンセプト]
本当の所の Shift-JIS の「構想」は、ISO-2022 が提唱するような“エスケープ・シーケンスを用いて無数の文字集合を利用可能にすること”ではなく、“JIS X 0201(8bit) と JIS X 0208 の文字集合だけでいいからエスケープ・シーケンスのような余分な情報を付加することなく、文字コードの値を解析するだけで両者の文字集合の区別を可能にすること”にあります。そして Shift-JIS の「正体」もやはり、それを可能にした“JIS X 0208 の文字集合のコード・ポイントを JIS X 0201(8bit) と判別できる位置にずらす(これが "Shift-JIS" の名のゆえん)一連のルール”にあります。ところが Shift-JIS は、 JIS X 0201(8bit) と JIS X 0208 という複数の文字集合を扱っていながら、ISO-2022 のようにそれを論理的に切り替えながら利用するのではなく、混在させて扱う仕組みであるためにそれぞれの文字集合の立場が明確ではなく、Shift-JIS は JIS X 0201(8bit) と JIS X 0208 の文字集合を含む“文字集合”である、のように認識されることがあります。さらに、ソフトウェア・ベンダは JIS X 0208 文字集合内の未定義領域に独自の文字(これは「外字」や「機種依存文字」などと呼ばれる)を割り当てた JIS X 0208 に“よく似た”文字集合を含む Shift-JIS を実装するため、事態はより複雑に把握しにくくなってしまっています。(とはいえ、これは自然な流れであり仕方ないことでもあります。)[アイディア]
Shift-JIS の“エスケープ・シーケンスを用いずに JIS X 0201(8bit) と JIS X 0208 の文字集合を複合利用するためのアイディア”は意外に単純なものです。要するに問題は、出現したある単バイトが JIS X 0201(8bit) の1バイト文字なのか、それとも JIS X 0208 の2バイト文字の1バイト目なのか、が判断できればよいので、Shift-JIS は JIS X 0201(8bit) 文字集合のうち未定義となっている領域の文字コードを JIS X 0208 の2バイト文字の1バイト目として機能させる、という解を見出しました。これにより、必然的に2バイト文字の1バイト目が取り得る値は限定されてしまいますので、JIS X 0208 のコード・ポイントをシフトさせる必要性はこのような理由で生じたのです。
(JIS X 0201(8bit) の未定義領域については、当の節の表で確認可能です)[アイディアの実現,利用するコード範囲]
Shift-JIS のアイディアは単純なものでしたが、それを可能にするために発生した「コード・ポイントのシフト作業」は、文字コードの整合性を保ちつつコード・ポイントのシフトを行うための変換公式が必要になり、プログラミングの知識を要される少々難解なものです。この文書ではそれについての詳細には触れていません(*)。
Shift-JIS は、2バイト文字の1バイト目に、未定義となっている JIS X 0201(8bit) の 0x80 ~ 0xA0 及び 0xE0 ~ 0xFF の範囲のうち、0x81 ~ 0x9F 及び 0xE0 ~ 0xFC の範囲を、そして2バイト文字の2バイト目には 0x40 ~ 0x7E 及び 0x80 ~ 0xFC の範囲を割り当てています。2バイト目のコードが 0x40 以降からなのは、まず制御文字に当るコードを除いたことと、2バイト文字を認識しない処理系を意識して、特殊な意味を付与し利用されることの多い各種の記号文字を含む 0x21 ~ 0x3F の範囲を避けたことに理由があります。ただし、これで全ての記号文字を排他できた訳ではなく、特に 0x5C (JIS X 0201 では“円記号”)を除外していないことは後に多くの人を悩ますことになりました。 ところで JIS X 0208 では文字コード領域を 94 * 94 = 8836 確保していましたが、それに対し Shift-JIS の確保する領域は 11280 と JIS X 0208 よりもかなり多めにとられています。この数値は、Shift-JIS では JIS X 0208 とは異なり文字集合の体系が分断されてコード領域に収められているという理由で多少回りくどく計算されます。
( ( 0x9F - 0x81 + 1 ) + ( 0xFC - 0xE0 + 1) ) * ( ( 0x7E - 0x40 + 1 ) + ( 0xFC - 0x80 + 1) ) = 11280
つまり、ソフトウェアの内部的な文字エンコーディング方式に Shift-JIS を採用すると、2444 の新たな領域が生まれることになります。そして、この領域にソフトウェア・ベンダが外字を割り当てることを規制する者はいません。結果的に JIS X 0208 には無い文字、Shift-JIS でしか利用できない文字が存在することになってしまいました。(* 興味が湧けばその辺のところも追求したいところですが、私の目的は当初から「文字コードの全体像を把握する」ことに集約しているため、やや局所的な知識という感のあるこの変換公式についてはそれほど興味が湧きませんでした。私は全てを網羅しようと考えている訳ではありません。なお、この変換公式のことを調べたい方は「パソコンにおける日本語処理/文字コードハンドブック(著:川俣晶)」という書籍に付属(CD-ROM)する JRConvert という Java プログラムのソースを参考にするとよいかもしれません。)
Shift-JIS による1バイト文字と2バイト文字の扱いのコンセプトのイメージを以下に示します。これは、JIS X 0208 のコンセプト・イメージと見比べると、その違いがよく分かります。
【Shift-JIS コンセプト・イメージ】 
[データ量はテキスト列で判断できる?]
例として、“珈琲はcoffee”という文字列があるとします。文字エンコーディングに Shift-JIS を利用している環境下では、この文字列のデータ量を「12バイトである」(2バイト文字×3 + 1バイト文字×6)と見ただけで判断することができます。文字エンコーディング方式の中では“特殊派生種”に分類される Shift-JIS のこの“特殊利点”はあまりに定着化し過ぎてしまい、特殊な事情のはずが常識の事情になってしまっているという面白い現象(?)が起こっています。私自信、「エスケープ・シーケンス」などという存在を知ったときには随分と驚いたものです。[仲間はずれの“補助漢字”]
JIS は JIS X 0208 の漢字不足に対する抗議に応えて“補助漢字”と通称される JIS X 0212 を1990年に制定しましたが、抗議があったにも関わらず、この規格はなかなか一般に浸透しませんでした。その理由の一つとして、そのとき既にパソコン業界で大きなシェアを占めていた Shift-JIS にはこの補助漢字の文字集合を収録するだけの空き領域がなかったことが挙げられます。Shift-JIS は JIS X 0208 よりも多くの領域を確保している、と前述しましたが、それでも補助漢字を収めるだけのスペースはなかったのです。という訳で補助漢字は文字コードの華やかな(?)世界から仲間はずれにされ続けてきましたが、ようやく最近(という程でもないか)になって EUC-JP や Unicode などに救いの手を差し伸べられているようです。[開発元と制定年]
具体的な情報がつかめないので触れていませんでしたが、Shift-JIS を開発したのはどこの会社で、一体いつ頃誕生したのでしょう?私の手元の資料によれば、アスキー・マイクロソフトという会社が MS-DOS の日本語化作業の過程で開発した、と記述されています。誕生した正確な年は不明です。公的な規格とは違い、はっきりと明文化された発表などはなかったのでしょう。もともとは限られた範囲の私的な規格だったのが「便利」という一言に尽きる理由で自然に広まって行ったのだと推測されます。 - ISO 2022
-
[概要,位置づけ]
ISO-2022 は 7bit 又は 8bit をベースとしたテキスト・データ列の中で複数の文字集合を混在利用するための枠組みを提供する規格です。文字エンコーディング方式の一種といえますが、この規格の提唱する仕組みをそのまま実装し、運用されるケースはほとんど見られません。ISO-2022 は少々大げさである程に事細かにその内容を取り決めており、この規格に完全準拠するのは困難で、またその必要もない、という理由からです。その代わり、ISO-2022 は複数の文字集合を利用するための有用なガイドラインとして幾つかの他の文字エンコーディング方式に部分的に参照される形で活用されています。なお、国内では「JIS X 0202 情報交換用符号の拡張法」がこれに対応する規格として発行されています。[構想概念の抽象的解説]
ISO-2022 が提唱するのは複数の文字集合をテキスト・データ列の中で混在利用するための一連のルール/概念です。7bit をベースとしたものと 8bit をベースとしたものの二通り提唱されていますが、基本的な構想においては両者に差異はありません。
基本的な構想とは次のようなものです。この項では、具体的な実装面においての 7/8bit の微妙な差異をカプセル化するため、抽象的な解説に留めています。- 7/8bitの文字コード領域を「制御文字の領域」及び「図形文字の領域」に明確に区分割する。
- 文字コード領域とは別に、四つの「文字集合収容空間」を設け、ここに収容した文字集合を文字コード領域の図形文字の領域 に「呼び出す」ことによって利用する。
- 諸々の文字集合を 94, 96, 94n, 96n 文字集合のどれかに分類し、文字集合収容空間 に「指示する」ことによって収容する。
【ISO-2022 コンセプト・イメージ】 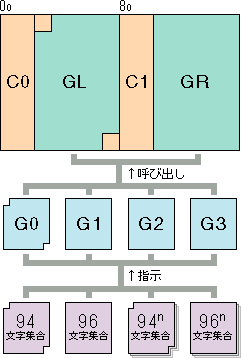
[呼び出し(ロッキング・シフト,シングル・シフト)]
呼び出しとは、何を呼ぶのかと言うと 文字集合収容空間の内の一つ を呼ぶことですが、自然な解釈をすると“図形文字の領域が参照する文字集合収容空間を切り替える”と言うことも出来ます。すなわち、図形文字の領域に文字集合収容空間にある文字集合を“移動”するのではなく、図形文字の領域から“参照”する、ということです。このため、既に参照している文字集合収容空間に指示を行い別の文字集合を収容した場合、その文字集合収容空間を改めて呼び出し直す必要は無い、ということになります。
呼び出しには、「ロッキング・シフト」と「シングル・シフト」という動作の異なる二種類の方式があります。この違いは実に単純です。ロッキング・シフトは、次の呼び出しが起こるまで指定された文字集合収容空間を参照し続けます。それに対し、シングル・シフトは一文字分(文字集合によりバイト数は異なる)だけ指定された文字集合収容空間を参照し、その後は直前の文字集合収容空間を参照し直します。このような、両者のシフト操作の使い分けは、この規格を実装する文字エンコーディングのコンセプトにより各文字集合の使用頻度に開きが起こることを考慮してです。[構想概念の具象的解説:7bit]
7bit の構想概念では、それぞれの領域,空間に以下のような称号が与えられています。(実はこれらの称号の発祥は不明)
制御文字集合 C0, C1 (詳細は JIS X 0211 の節を参照)は 7bit では両方収めることが出来ないので交換利用することになっています。また 8bit では二つある図形文字の領域が 7bit では GL の一つしかありません。GL はほとんどの場合、ASCII や JIS X 0201(Roman) などの ASCII系文字集合の領域として扱われるため、SPC (0x21) と DEL (0x7F) を塞いでしまう 96単位系文字集合を参照することは推奨されません。「制御文字の領域」 0x00 ~ 0x1F: C0, C1 (交換利用) 「図形文字の領域」 0x20 ~ 0x7F: GL 「文字集合収容空間」 G0 G1 G2 G3指示により G0 ~ G3 に収容された文字集合を GL, GR から呼び出すことで利用します。7bit では以下のようなエスケープ・シーケンスを用います。8bit の場合と同様、シングル・シフト可能な文字集合収容空間は G2, G3 に限る、という制約があります。 また、8bit との差異の注意点として、文字コードは同一でありながら SI, SO の名称が異なること、SS2, SS3 の名称は同一でありながら文字コードが異なること、があります。「ロッキング・シフト」 GL <- G0: SI (Shift In (0x0F)) GL <- G1: SO (Shift Out (0x0E)) GL <- G2: LS2 (Locking Shift 2 (0x1B 0x6E)) GL <- G3: LS3 (Locking Shift 3 (0x1B 0x6F)) 「シングル・シフト」 GL <- G2: SS2 (Single Shift 2 (0x1B 0x4E)) GL <- G3: SS3 (Single Shift 3 (0x1B 0x4F))
[構想概念の具象的解説:8bit]
8bit の構想概念では、それぞれの領域,空間に以下のような称号が与えられています。7bit と大差はありませんが、C0, C1 が独立した領域を持つこと、図形文字の領域に GR が加わったことが違います。文字集合収容空間はまったく同一です。「制御文字の領域」 0x00 ~ 0x1F: C0 0x80 ~ 0x9F: C1 「図形文字の領域」 0x20 ~ 0x7F: GL 0xA0 ~ 0xFF: GR 「文字集合収容空間」 G0 G1 G2 G38bit では図形文字の領域に GR が加えられたことに伴い、エスケープ・シーケンスにも GR を扱う為の拡張が加えられています。注意点として、GR に G0 を呼び出すことは出来ない、ことが挙げられます。(構想概念の具象的解説:7bit の項も参照のこと)「ロッキング・シフト」 GL <- G0: LS0 (Locking Shift 0 (0x0F)) GL <- G1: LS1 (Locking Shift 1 (0x0E)) GL <- G2: LS2 (Locking Shift 2 (0x1B 0x6E)) GL <- G3: LS3 (Locking Shift 3 (0x1B 0x6F)) GR <- G1: LS1R (Locking Shift 1 Right (0x1B 7E)) GR <- G2: LS2R (Locking Shift 2 Right (0x1B 7D)) GR <- G3: LS3R (Locking Shift 3 Right (0x1B 7C)) 「シングル・シフト」 GL <- G2: SS2 (Single Shift 2 (0x8E)) GL <- G3: SS3 (Single Shift 3 (0x8F))
[指示]
前述の通り、指示 は文字集合収容空間(G0 ~ G3)に、ある特定の文字集合を収容するための命令です。7bit, 8bit とも差異はありませんが、幾つかの例外的な決まりについては注意が必要です。
指示のエスケープ・シーケンスの連なりを抽象的に表現すると次のようになります。【】で囲まれる表名中の記号を指定している個所については、後記する表を参照してください。なお、各々のシーケンスは 慣用的に ASCII文字で表現しますが、本来はその文字コードが正しいところです。- エスケープ・シーケンスの始まりを表す ESC (0x1b)
- もし、非単バイト文字集合ならば $ (0x24)
- 【文字集合収容空間及び文字集合基本単位の対象別記号表】の内の一つ
- 【ECMA登録制文字集合対応記号表】の内の一つ
【文字集合収容空間及び文字集合基本単位の対象別記号表】 94単位文字集合 96単位文字集合 G0 ( (0x28) G1 ) (0x29) - (0x2D) G2 * (0x2A) . (0x2E) G3 + (0x2B) / (0x2F)【ECMA登録制文字集合対応記号表】 ■単バイト94単位 ISO-646 IRV @ US ASCII B JIS X 0201(Katakana) I JIS X 0201(Roman) J ■非単バイト94単位 JIS X 0208:1978(旧JIS漢字) @ JIS X 0208:1983(新JIS漢字) B JIS X 0201:1990(補助漢字) D ■単バイト96単位 ISO-8859-1(Latin-1) Aエスケープ・シーケンスの例を幾つか挙げましょう。ASCII を G0 に指示 ESC ( B JIS X 0201(Katakana) を G2 に指示 ESC * I JIS X 0208:1983 を G1 に指示 ESC $ ) B
例外として、この規格の古い実装系(ISO-2022-JPなど)では非単バイト文字集合の指示において($ があるとき)「【文字集合収容空間及び文字集合基本単位の対象別記号表】の内の一つ」が省略されている、ということが挙げられます。古い規格では、非単バイト文字集合の指示は G0 に限定されていた、ということらしいです。また、表を見ると、96単位文字集合の G0 への指示は「 , (0x2C)」 が対応しそうに見えますが、これは使用されないことになっています。普段、デフォルトで利用される G0 の SPC, DEL が置き換えられてしまうと何かと困るからでしょう。
文字集合に対応する記号は ECMA(欧州計算機製造業者協定)という組織で一貫整理されており、重複することのないよう登録制になっています。[利用できる文字集合]
ISO-2022 はこの世に存在する如何なる文字集合も扱える、という訳ではなく、利用可能とされる文字集合は、その数が 94, 96, 94n, 96n のどれかに適合するものでなければなりません。そのため ISO-2022 制定以降に登場した ISO-8859, JIS X 0201, JIS X 0208 などは全てこの条件に適うよう考慮され、設計されています。なお、制定以前から存在した重要な文字集合である ASCII や ISO-646 も当然ながら条件に適っています。 - ISO-2022-JP
-
[概観]
ISO-2022-JP はインターネット上で日本語をやり取りするための7bitベース文字エンコーディング方式を定めた規格であり、俗に“JISコード”と呼ばれます。この規格は名前から推測できるように ISO-2022 のサブセットであり、そのアプローチは ISO-2022 のコンセプトに当てはめて考えることができます。具体的な内容は RFC-1468 (タイトル:Japanese Character Encoding for Internet Messages) に記述されていますが、最初に仕様が明確化されたのは JUNET と呼ばれる実験用ネットワークにおいて、とのことです。
RFC-1468 のタイトル中の "Internet Messages" の部分は、インターネット上のサービスである、メール及びニュースの総称だと考えてほぼ間違いはありません。日本のメールやニュースでは現在(2002.06.30)標準的に ISO-2022-JP が用いられています。なお、WWW では通常 ISO-2022-JP ではなく Shift-JIS もしくは EUC-JP が用いられます。[内容]
ISO-2022-JP を ISO-2022 のコンセプトと照らし合わせて考えてみましょう。まず ISO-2022-JP は、7bit をベースとした文字エンコーディング方式なので、当然 ISO-2022(7bit) を基にしており、C0 及び GL の概念しかありません。G0 ~ G3 についても最初の G0 しか用いていません。そして ISO-2022-JP には、G0 が GL に既に呼び出されているという前提条件があるので「呼び出し」は一切用いず「指示」のみで文字集合の切り替えを行う、という特徴があります。
指示で利用されるエスケープ・シーケンス及びそれに対応する文字集合は次の四つです。16進数表記 ASCII文字表記 対応する文字集合 1B 28 42 ESC ( B ASCII 1B 28 4A ESC ( J JIS X 0201(Roman) 1B 24 40 ESC $ @ JIS X 0208:1978(旧JIS漢字) 1B 24 42 ESC $ B JIS X 0208:1983(新JIS漢字) JIS X 0208 における ISO-2022 の実装によく似ていますが、 JIS X 0201(Katakana) が存在しません。つまり ISO-2022-JP では、いわゆる“半角カタカナ”は利用されません。
- 未検証の文字エンコーディング方式
-
次に列挙する項目は、その存在は確認していたものの、諸々の事情で検証まで至ることの出来なかった文字エンコーディング方式らです。機会があれば検証に踏み込もうと思っています。
- EUC-JP
- Base64
- Quoted-Printable
- 文字コード関連リンク
-
やや易しく、情報 △:
- ミケネコの文字コードの部屋 http://www.mikeneko.ne.jp/~lab/kcode/index.html
- euc.JP http://euc.jp/ #詳細で分かりやすい各種文字コードの解説
- 日本語と文字コード http://www.kanzaki.com/docs/jcode.html
- http://www.asahi-net.or.jp/~wq6k-yn/(文字コードについてのメモ)
- http://www.zukeran.org/shin/(ず?多量の文字コード関連リンク)
- http://www.d2.dion.ne.jp/~imady/index.html(いまでぃさんのサイト)
- 地球流体電脳倶楽部-文字コード論 http://dennou-t.ms.u-tokyo.ac.jp/arch/zz1998/mozi/SIGEN.htm
- Koichi Yasuoka http://kanji.zinbun.kyoto-u.ac.jp/~yasuoka/index.html #各種文字集合の配置マトリクス画像,漢字袋
- http://www.iso.org/iso/en/ISOOnline.frontpage(ISO)
- http://www.asahi-net.or.jp/~ez3k-msym/index.htm(文字・コードに関する覚え書き)
- IKEDA Shoju's Home Page http://member.nifty.ne.jp/shikeda/index.html
- ほら貝 http://www.horagai.com/www/home.htm
- JIS X 02XX の研究 http://www.geocities.com/mogukun/jis/
- e-worda:ASCII文字コード表 http://www.e-words.ne.jp/page.asp?p=r-ascii
- HyperRFC - Hyper-linked RFC http://www.csl.sony.co.jp/rfc/
- 日本語RFC http://www.se.hiroshima-u.ac.jp/~isaki/rfc/
- 文字コード変換ソフトのリンク
-
Windows:
- Character Code Filter:
http://www.vector.co.jp/pack/win95/util/text/conv/code/ - EnJESU:
http://www.alles.or.jp/~xendo - QKC-Quick KANJI code Converter:
http://hp.vector.co.jp/authors/VA000501/ - エントランス:
http://www.asahi-net.or.jp/~TC7Y-SSGW/entrans/ - jme 漢字コード変換プログラム:
http://www3.airnet.ne.jp/saka/ - nkf Win32版:
http://www.vector.co.jp/soft/win95/util/se031296.html
- Mac nkf:
http://www1.u-netsurf.ne.jp/~future/ - ふみばこ:
http://hp.vector.co.jp/authors/VA001080/ - Multi Text Converter:
http://www.aay.mti.ne.jp/~akira-h/
(*これらのリストは「図解でわかる文字コードのすべて(著:清水哲郎)」219pを参考にしました。各々を確認したわけではないので、現在では既に入手が困難なものが含まれている可能性をご承知ください。2002.05.21)
- Character Code Filter:
- ASCII文字テーブル出力スクリプト
-
以下のPerlスクリプトは【ASCII文字テーブル】の二行目以下を出力するときに記述したものです。(制御文字は ^ で出力し、後で置換えました。背景の色付けは、クラス名を付けてスタイルシートにより行っています)
foreach $first (0..15){ printf "<tr><th>%X</th>", $first; foreach $second (0..7){ $num = $second*16 + $first; if($num <= 0x20 || $num == 0x7F){ print "<td class=\"control_char\">^</td>"; }else{ printf "<td>%s</td>", pack("C", $num); } } print "</tr>\n"; } - JIS X 0201(8bit)文字集合出力スクリプト
-
次のPerlスクリプトは【JIS X 0201 - 8bitベース文字集合】の二行目以降を出力するために「ASCII文字テーブル出力スクリプト」にほんの少し手を加えたものです。制御文字の略号を書き写すのが面倒かと思いましたが、テキストエディタにブロック選択の機能が付いてたので意外とあっさり済んでしまいました。
foreach $first (0..15){ printf "<tr><th>%X</th>", $first; foreach $second (0..15){ $num = $second*16 + $first; if($num <= 0x20 || $num == 0x7F){ print "<td class=\"control_char\">^</td>"; }elsif($num >= 0x80 && $num <= 0xA0 || $num >= 0xE0){ print "<td class=\"undefined\"></td>"; }else{ printf "<td>%s</td>", pack("C", $num); } } print "</tr>\n"; } - あとがき
- 2ヶ月くらいでしょうか。なんともだらだらと検証して参りました(^^;最後の方はだんだんやる気無くなってきて、幾つか未検証のまま、とりあえず完成となりました。でも随分と文章書きました。自分なりに結構うまくなったかな、と思います。文章は書けば書くほど上手になるというのは本当ですね。これは“悩めば悩むほど”と言い換えてもいいかもしれません。文章だけでなく、なんでも同じなんですね。さて・・・次は何をやろうか・・。
 受付状況
受付状況